プロセスとスレッドの違いとは?超わかりやすく解説!【図解とプログラム付き】


こんにちは!
今井(@ima_maru)です。
本記事では、プロセスとスレッドについて軽く触れた後に、マルチスレッドプログラミングの危険性を紹介します。
また、実際にプログラミングして、スレッドがどのように動くのかを確かめていこうと思います。
それでは解説していきます!
もくじ
結局「プロセス」と「スレッド」って何が違うの?
結局のところ、プロセスとスレッドは何が違うのでしょうか。
そもそも、プロセスとスレッドはWordとExcelといった対等な関係ではありません。
しいて言うなら、プロセスはWordであり、スレッドはWordの画面描画機能やキーボード入力機能などです。
つまり、階層が違う概念なのです。
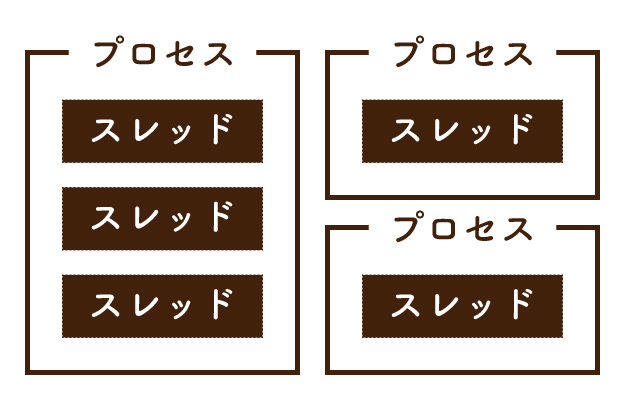
OSによってプロセスは管理され、プロセスによってスレッドは管理されます。
また、OSは各プロセスに対して異なるメモリ領域を提供できますが、プロセスはスレッドに対してそれを行うことができません。
なので、WordとExcelはメモリ領域を共有することはありませんが、Wordの画面描画スレッドとWordのキーボード入力スレッドは同じWordというプロセスのメモリ領域を共有するのです。
そのため、プロセス間では影響は及ぼさないけど、スレッド間ではメモリ領域をちゃんと管理しないとバグるのです。
プロセスとは?
プロセスとは、OSが実行しているプログラムのインスタンスになります。
ほぼほぼ「プロセス」=「実行中のプログラム」と思っていただいて大丈夫です。
例えば、Word・Excel・chrome・メモ帳などはそれぞれ1つのプロセスになります。
これらのプロセスがOSによって並列処理されることを「マルチプロセス」と呼びます。
いろんなプログラムが同時に動くのは、汎用的なOSでは当たり前のことですね。つまり、WindowsやMacなどは、マルチプロセス(マルチタスク)のOSということになりますね。
プロセスはOSによって管理されていて同じメモリ領域を共有しない
プロセスが使用していいメモリ領域はOSによって管理されています。
そして、各プロセスは同じメモリ領域を一切共有しません。
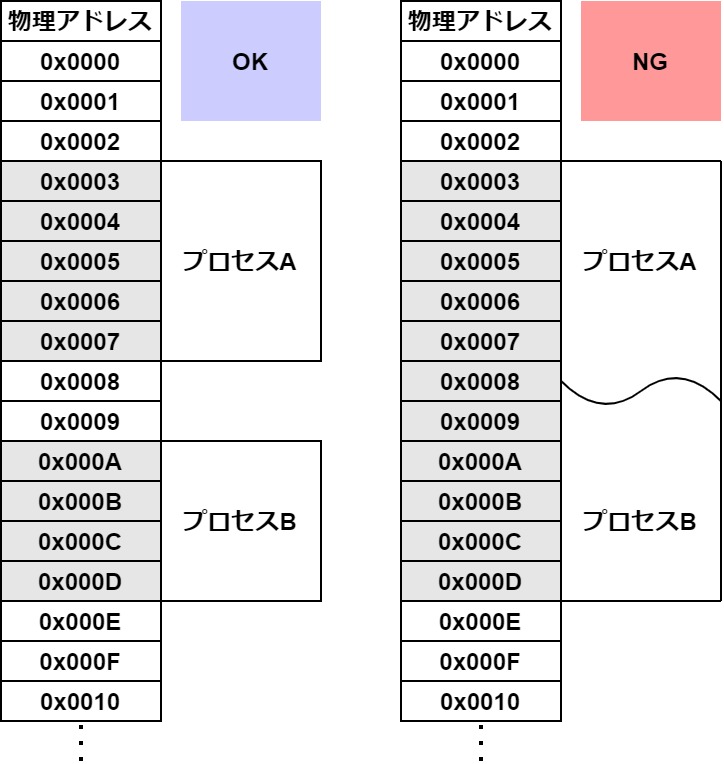
なので、メモ帳に何か文字を書いたからと言って、Wordに反映されることはあり得ないのです。
そもそもメモリ領域が全く別なのですから。
これからいえることは、あるプロセスの処理は、ほかのプロセスに一切影響を与えないということです。
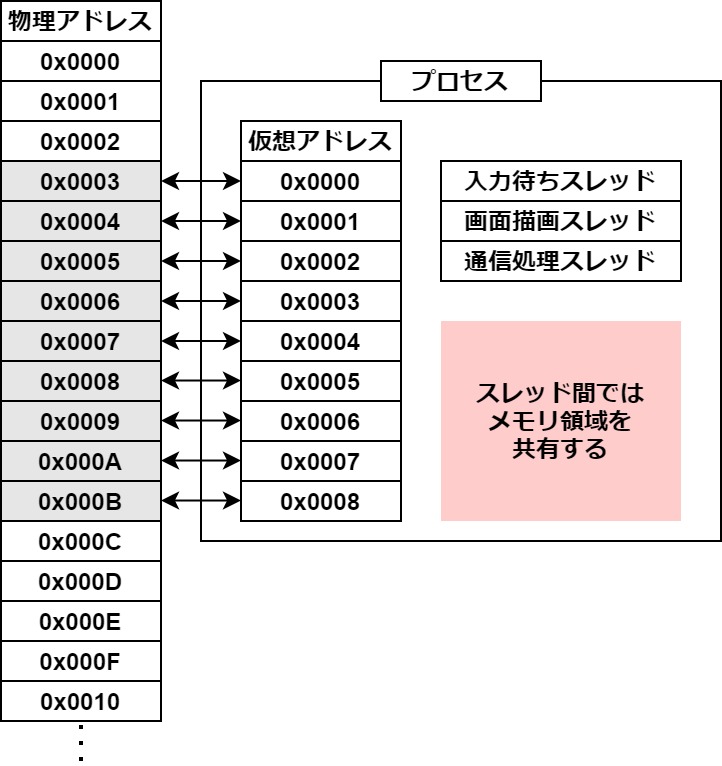
プロセスはメモリ領域に仮想アドレスでアクセスする
プロセスが使用していいメモリ領域は、あらかじめOSから与えられていて決まっています。
そして、OSからメモリ領域にアクセスするために与えられるのが「仮想アドレス」です。
仮想アドレスは、メモリ領域の通し番号のようなもので、0x00000000~0x0000FFFFといったようなものです。
これらはOSによって確保された実際のメモリアドレス=物理アドレスと結び付けられています。
以下のようなイメージです。
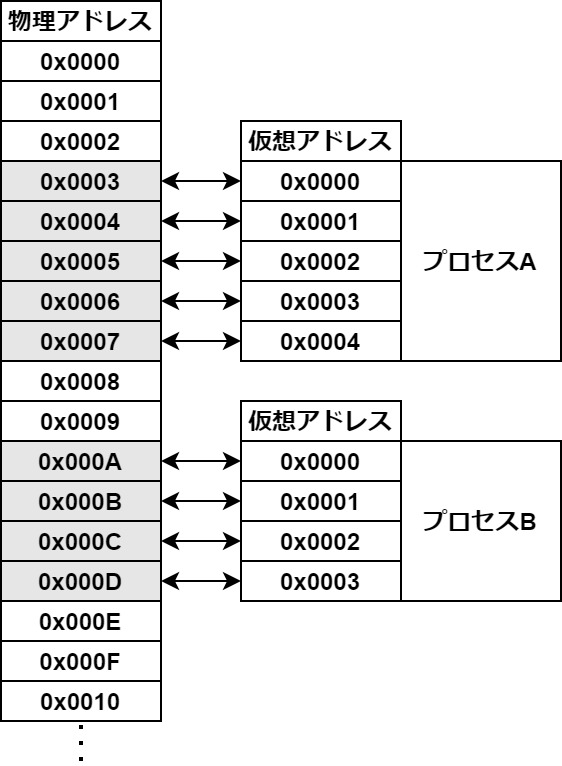
この仕組みは「メモリアドレスの抽象化」と「範囲外アクセスの防止」という二つのメリットを生みます。
プロセスのメリット
- メモリアドレスの抽象化:プロセス側で物理アドレスを意識しないで良いこと
- 範囲外アクセスの防止:プロセスが他のプロセスが扱うメモリに影響を与えないこと
もしほかのプロセスのメモリ領域にアクセスしたい場合は、OSが用意しているAPIを用いる必要があります。
スレッドとは?
スレッドとは、CPUから見たプログラムの「実行単位」です。
CPUは基本的に1つのコアで1つの処理しか実行することはできません。
つまり、4コアのCPUでは同時に実行できる処理は4つまでということです。
その処理単位がスレッドと呼ばれます。
言い換えれば、「1つのコアに割り当てられるのは1つのスレッドまで」ですね。
スレッドはプロセスに含まれる
スレッドというのは、プロセスに含まれます。
例えば、
- 「ユーザーからの入力を受け取るスレッド」
- 「画面描画をするスレッド」
- 「音楽を再生するスレッド」
- 「インターネット通信を行うスレッド」
などなど、1つのプロセス内でも複数の機能でスレッドを分けて実装することができます。
呼ばれ方としては、
シングルスレッドのプロセス:1つしかスレッドを持たないプロセス
マルチスレッドのプロセス:複数スレッドを持つプロセス
このように呼ばれます。
もちろん1つのスレッドのみで機能させることも可能ですが、複数のスレッドを使うことで並列処理の簡易化などのメリットを生みます。
スレッドはプロセス内の同じメモリ領域を共有する
スレッドは、スレッド同士で同じメモリ領域を共有します。(危険)
ここがプロセスと違います。
異なるプロセス間は、OSによってメモリ領域を区別されているのでメモリを共有することはありませんが、同一プロセスのスレッド間ではそのプロセスが保有しているメモリ領域を共有します。
そのため、スレッドAとスレッドBが同じメモリ領域を同時に書き換えようとしたとき、バグが起こったりもします。
このようなことが起こらないために、マルチスレッドの環境では、適切なメモリ管理を行わないといけません。
この適切なメモリ管理のことをスレッドセーフ(な設計)と言ったりします。
マルチスレッドの目的は「並列処理の簡略化」を可能にする
マルチスレッドにすることの目的は、主に「並列処理の簡略化」です。
例えば、シングルスレッドであると、ものすごく重い処理をしているときに画面更新が行われず画面がフリーズしているように見えます。
これを解消するには、画面更新の処理をその重い処理の間に細切れに挟む必要があります。
もちろんシングルスレッドでもそのような処理を書くことは可能なのですが、マルチスレッドで書けば、もっと簡単に並列処理を実現できるのです。
このメリットは、それぞれの処理に注力できること。
重い処理は重い処理だけを1つのスレッドとして書けばよくて、画面更新の処理はまた違ったスレッドで書けばよいのです。
そしてそれらのスレッドはコンテキストスイッチと呼ばれる機能によって切り替えられます。
マルチスレッドはマルチコアCPUにおいての高速化にも使われる
マルチスレッドにすると、CPUの複数のコアに処理を割り当てることができます。
同じ作業量でも、1人と2人では処理スピードも2倍違うでしょう。
それと同じで、複数のコアにうまく割り当てることができれば、高速化が期待できます。
ただ注意しないといけないのが、シングルコアの場合です。
シングルコアの場合、スレッドは同じコアで切り替えられるので、その切り替え分で逆にパフォーマンスが落ちます。
マルチスレッドプログラミングとは「並列処理」
マルチスレッドプログラミングとは、端的に言えば並列処理です。
スレッドを高速で切り替えることであたかも同時に処理しているように見せる
マルチスレッドは同時に複数のスレッドが処理を行っているように思えますが、特殊な状況でない限り「同時」ではありません。
というのは、CPUのコアが複数ある場合は、各コアで同時に処理できるのですが、たかが4つや8つのコアで100や200といったスレッド数を同時に処理することはできません。
そこでどうマルチスレッドを実現するかというと、
「人間にはわからないほど高速でスレッドの切り替えを繰り返して、あたかも同時に処理を行っているように見せる」
ということを行っています。
C++の標準ライブラリのthreadで確かめてみましょう。
実行する処理
- スレッドAを作成し関数func_a()を実行させる(’a’を表示する)
- スレッドBを作成し関数func_b()を実行させる(’b’を表示する)
#include <iostream>
#include <thread>
using namespace std;
void func_a()
{
for(int i = 0; i < 10000; i++)
cout << 'a';
}
void func_b()
{
for (int i = 0; i < 10000; i++)
cout << 'b';
}
int main()
{
//スレッド作成
thread threadA(func_a);
thread threadB(func_b);
//スレッド終了待ち
threadA.join();
threadB.join();
return 0;
}bbbbbbbbbbbaaaaaaaaaaaaaaabbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaabbbbbbbbbbbbbbbbbbbbaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaabbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaabbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb...aと表示しているのはスレッドAです。bはスレッドBです。
この実行結果からもわかるように、スレッドAとスレッドBの切り替えを繰り返し行うことにより、あたかも同時に処理しているかのように見せるのです。
試したい方は以下からどうぞ。
スレッドの切り替わるタイミングによっては致命的なバグを引き起こす可能性がある
マルチスレッドでは、スレッドを高速で切り替えながら複数の処理を実行しています。
また、スレッドの切り替わるタイミングを正確に予想することは非常に困難です。
そんな、スレッドの切り替わるタイミングによっては、「複数のスレッドが同じリソースにアクセスしている状況」が発生することがあります。
この時に、「ある危険性」が生じます。
例えば、「同じ変数を参照しているときに、その値を変えようとしたとき」などに起こります。
何が起こるかというと、期待していた値にならないという現象が起こるのです。
実際にやってみましょう。やることは、
実行する処理
- sumの値を0にセット
- sumの値に+1を10000回実行する関数add_sum()を用意
- スレッドAとスレッドBを作成し関数add_sum()を実行させる
普通に考えれば、「+1」を10000回実行するスレッドが2個なので、sumの値は0から20000になるはずです。
ですがそうはいかないのです。
#include <iostream>
#include <thread>
using namespace std;
int sum = 0;
void add_sum()
{
for (int i = 0; i < 10000; i++)
sum++;
}
int main()
{
//初期値を表示
cout << "スレッド作成前 sum:" << sum << endl;
//スレッド作成
thread threadA(add_sum);
thread threadB(add_sum);
//スレッド終了待ち
threadA.join();
threadB.join();
//結果を表示
cout << "スレッド終了後 sum:" << sum << endl;
return 0;
}スレッド作成前 sum:0
スレッド終了後 sum:13362ですが結果は残念なことに「13362」。(実行するごとに変わる)
実際に皆さんも以下から何回か試してみてください。実行するごとに違う値が表示されるはずです。
これはどうしてでしょうか。
原因は、変数の値の一時保存にあります。
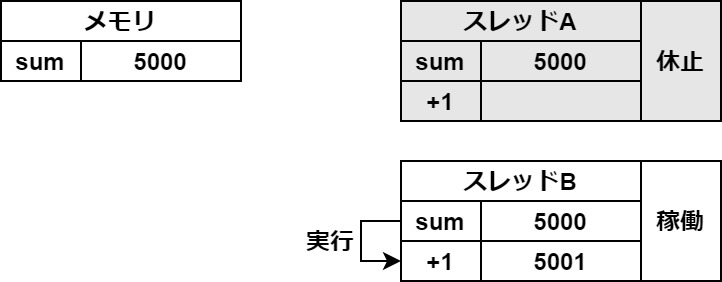
わかりやすいように、図を使って説明します。
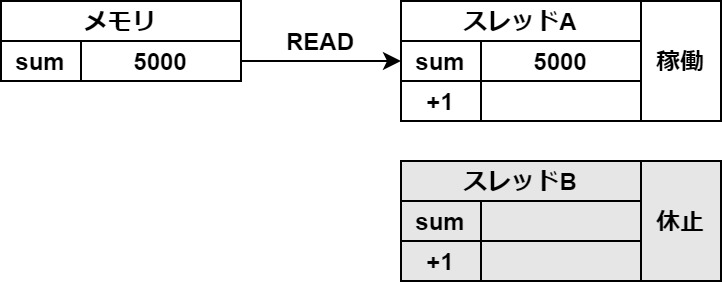
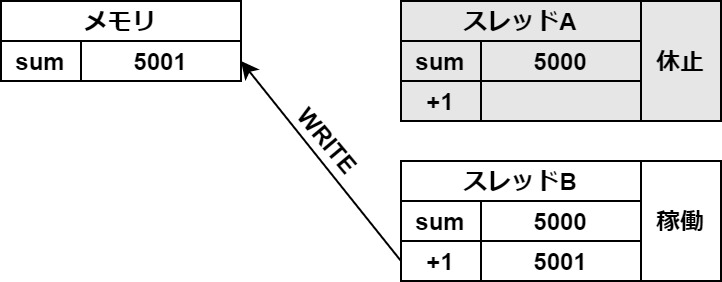
まずは、スレッドAがメモリから変数の値を一時保存領域に読み込みます。
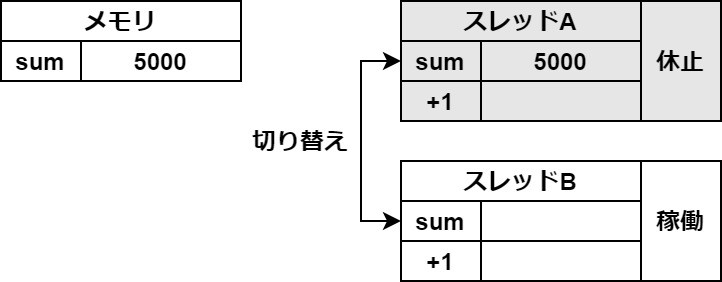
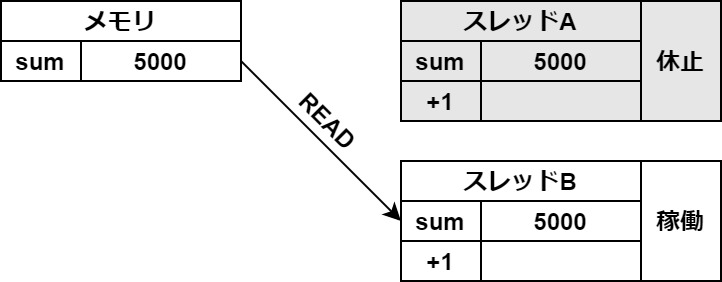
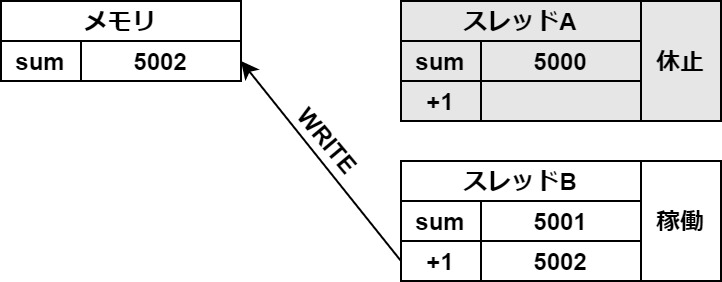
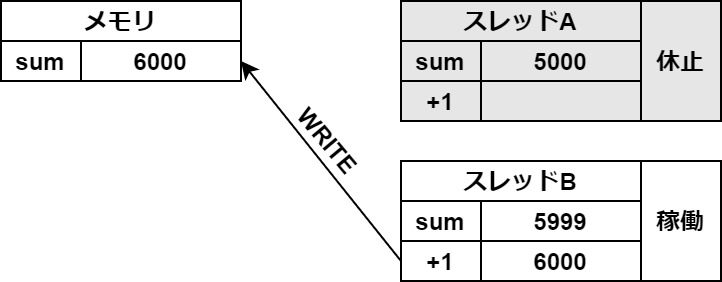
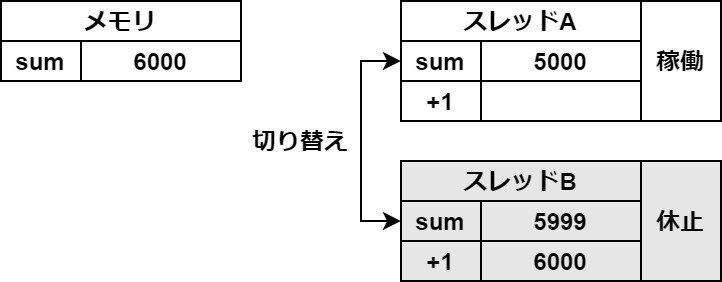
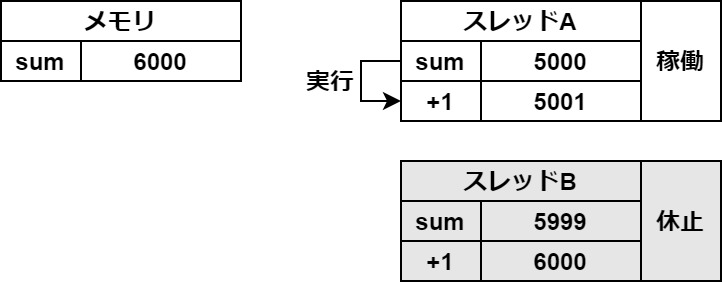
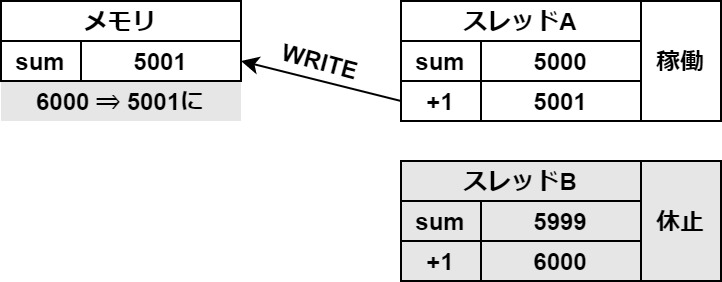
タブがあるので切り替えてご覧ください
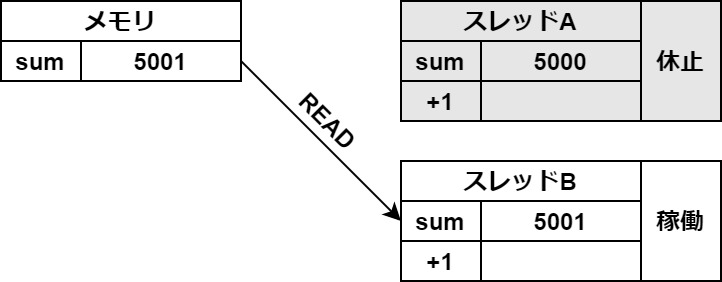
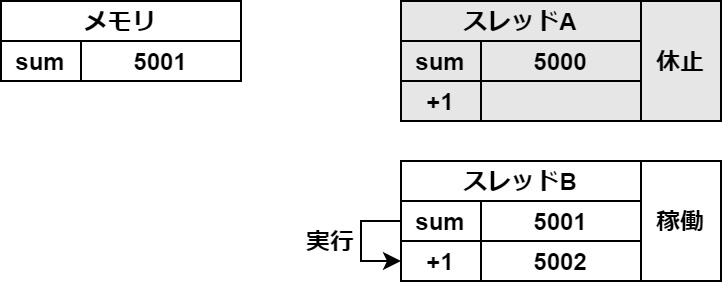
この一時保存がスレッドの切り替わりの時に起きてしまうと、このようなバグが起こります。
これが銀行のシステム内で起きたら大変ですね。
2つの100万円の振り込みが起こったのにもかかわらず、片方しか反映されないなんてなったら、消えてしまった100万円をどうするのでしょうか。
内容はちょっと違えど、以下のようなことです。
このようなことが起きないため、スレッドの危険性を排除するようなプログラムを書かなくてはいけません。
そのような設計方法をスレッドセーフといったりもします。
マルチスレッド関連の用語
ここでは、マルチスレッド関連でよく使われる用語について軽く触れておきます。
シングルスレッド
シングルスレッドとは、そのままの意味で、1つのスレッドしか持たない実行環境のことです。
処理は順序通りに行われるので、マルチスレッド特有の危険性がありません。
並列処理と逆の意味で、「逐次処理」といえばよいでしょうか。
マルチスレッド
マルチスレッドとは、複数のスレッドが並列で処理される実行環境のことです。
リソースの管理をしっかりと行わないと、再現性の低いバグ(稀に起こるバグ)を発生させる危険性があるので、注意が必要です。
スレッドセーフ
スレッドセーフとは、「マルチスレッドの実行環境でも大丈夫」という意味です。
先ほどのようなバグが起こらないように開発するということです。
例えば、複数のスレッドから同時にアクセスされる可能性があっても、読み取りのみであれば問題ありません。
つまり、読み取り専用のリソースはスレッドセーフといえます。
一方、値の変更が起こるリソースは、排他制御などで管理を行います。
排他制御
排他制御とは、あるスレッドがリソースにアクセスしているときは、ほかのスレッドがアクセスできないようにロックをかけることです。
ようは、変数に「スレッドAが使用中」とか「使用可能」とかの情報をつけるみたいなことです。
使用中であれば、ほかのスレッドは使用可能になるまで待つことになります。
こうすることで1つのリソースに複数の書き込みが同時に起こることを防止します。
シングルトン
シングルトンとは、インスタンスが1つしか生成できないように制限するという「デザインパターン」です。
つまり、全スレッドが同じインスタンスを共有するということになります。
これは、インスタンスを複数作ってしまうと不都合な場合に使われます。
例えば、インスタンス作成の処理が重い場合などです。
スレッドローカル
スレッドローカルとは、各スレッドが持つローカルな記憶領域です。
各スレッドが持っている作業スペースのようなものです。
マルチスレッドでは、各スレッドが一度この記憶領域に変数をREADして、処理を加えてからWRITEします。
先ほどの例のように、READとWRITEの間にほかのスレッドが行った処理は反映されないので、注意が必要ということなのです。
【ITエンジニア志望の学生限定】筆者が利用した就活エージェントを紹介!
「ITエンジニア志望だけど、就活って何から始めたらよいかわからない。」
「エンジニアになるには、どんなスキルがどのくらい求められるんだろう。」
このような悩みを抱えていないでしょうか?
実際私も「何から始めたらよいかわからない」状態のときがありました。
そんな方は、まず騙されたと思って「レバテックルーキー」というITエンジニア専門の就活エージェントに登録してみてください。
レバテックルーキーとは何ぞや!?
- エンジニア就活のプロが始め方やコツなどを教えてくれる。
- 自己分析を手伝ってくれる。
- 自分の求める条件に合ったIT企業をいくつも紹介してくれるため、探す手間が大幅に省ける。
- エントリーシートを加工して送ってくれるため、何枚も書かなくて良い。
- 紹介企業の質が高い。(ブラック企業には行きたくないね!)
- 紹介企業の詳細が一目でわかる資料が有料級。(これが無料はやばい)
- 面接官と繋がっているため、面接対策が異常に強い。どんな理由でお見送りになるかまで知れたのは『チート』だと思った。
- もちろん就活⇒内定まで全て無料!!
まだまだ魅力がありますが、それを書くと長くなってしまうので、気になる方は以下の記事をご覧ください。
あわせて読みたい

レバテックルーキーの評判は最悪?【22卒で利用したWebエンジニアが全て教えます】
こんにちは!今井(@ima_maru)です。 今回は、エンジニア就活に非常におすすめの「レバテックルーキー」についての紹介記事です。 私も22卒のエンジニア就活生としてレバ...
そんな「レバテックルーキー」ですが、サービスを受けるには2つの条件をクリアしている必要があります。
- 大学生・大学院生・専門学生・高専生・短大生である【文系・理系・情報系は問わない】
- ITエンジニア志望・もしくは興味がある
この条件に当てはまる方は、ぜひとも早めに登録することをおすすめします。(就活は早めにはじめると超有利になります。)
\ カウンセリング~内定まで"全て無料"! /
実際に僕もレバテックルーキーで最終内定を決めました。質の高い企業紹介と就活サポートが魅力の最強就活エージェントです。(ガチでオススメ!)
【優良企業に就職したい大学生へ】実務レベルのスキルを身に着けよう。
「ITエンジニアとして就職したいけど、プログラミングスキルがないのが不安。」
「大学でプログラミングの授業を受けたけど、全然自信がない。」
こんな悩みを持った大学生におすすめなのが「レバテックカレッジ」です。
「レバテックカレッジ」は大学生・大学院生専用のプログラミングスクールで、 Web開発の企業に求められる ECサイトやSNSの構築などのWebアプリ開発のスキルを学ぶことができます。
また、スキルを学ぶだけでなく就活のサポートもガッツリ受けられるので、プログラミングスキル習得から就活・内定まで一気通貫でサポートしてもらいたいという大学生の方にピッタリのサービスとなっています。
本気で学ぶならプログラミングスクールが効率的です。学生のうちに実務レベルのスキルを身に着けられれば、希少性の高い人材になれます。
まとめ
プロセスとスレッド、そしてマルチスレッドの危険性について書きました。
この辺はややこしくて頭が痛くなりそうですね。
自分も間違ってる点などあるかもしれないので、遠慮せずにご指摘いただければと思います。
当記事を読んでくださった方におすすめの記事!
以上「スレッドとプロセスの違いとは?マルチスレッドプログラミングの危険性を解説!」でした!
最後までご覧いただきありがとうございます。