強化学習とは?教師あり学習との違いなどをわかりやすく解説!


こんにちは!
現役Webエンジニアの今井(@ima_maru)です。
今回は、機械学習の手法である「強化学習」についての記事になります。
強化学習は、Googleが開発した囲碁AIの「Alpha Go」や「自動運転技術」などにも使われる、最先端の技術です。
そんな強化学習について詳しく解説していきます。
もくじ
強化学習とは何か?機械学習との違いは?

ここでは、強化学習の概要について解説します。
強化学習とは?
強化学習とは、機械学習の手法の1つで、以下のような表現をされます。
強化学習とは
- 試行錯誤を通じて「価値を最大化するような行動」を学習するもの
- システム自身が試行錯誤しながら、最適なシステム制御を実現する手法
- 環境との試行錯誤による相互作用を通して適切な行動戦略を獲得するタイプの機械学習
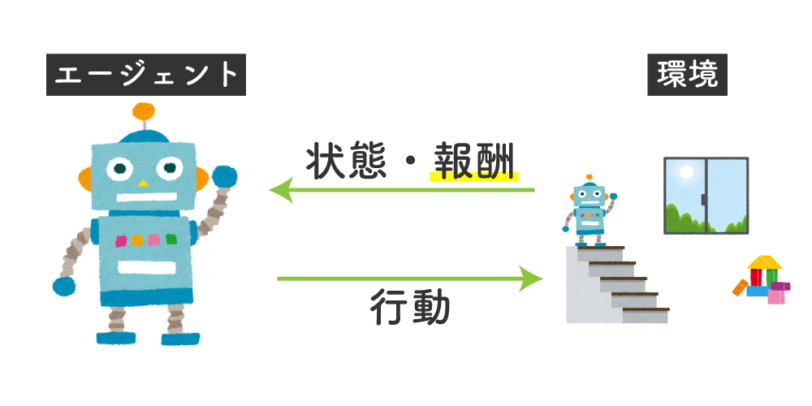
- ある環境内におけるエージェントが、現在の状態を観測し、取るべき行動を決定する問題を扱う手法
少し難しい定義ですが、抑えるべきポイントは「何を学習するか」と「どうやって学習するか」の2点です。
「何を学習するか」というと、「価値が高い行動」です。簡単に言ってしまえば、良い行動です。
「どうやって学習するか」というと、「環境内で試行錯誤をして学習する」です。
以上2点をまとめると、環境内で試行錯誤することで、価値が高い行動を学習するということになります。
これが、強化学習の根本的な考え方です。
例として、2足歩行のロボットの強化学習を当てはめて考えてみましょう。
2足歩行ロボットの強化学習
- 何を学習するか:姿勢を保ちながら歩くための関節の曲げ方など
- どうやって学習するか:とにかくいろんな歩き方を試しながら良さそうな歩き方を学習する
姿勢を維持しながら歩くためには、各関節の角度や曲げ方が重要になってきます。
要は、この例で学習するのは、どんな状態のときにどんな姿勢をとればよいのかということですね。
最初は何もわからない状態なのですが、何回も試行錯誤してるうちに、どうすれば良いかがわかってきます。
それらを学習していくこと、うまく歩けるように成長していきます。
4足歩行ですが、強化学習の動画がありましたので参考にどうぞ。
人間が物事を習得していく時の考え方も強化学習に近いといえます。例として、赤ちゃんがハイハイを覚えるとき、子供が初めて自転車に乗るときなどが挙げられます。
強化学習と機械学習の違い
強化学習は、機械学習ととても近い存在なので、混乱する方もいるかもしれません。
以下の図が示すように、機械学習の手法の1つに強化学習があるという関係になっています。
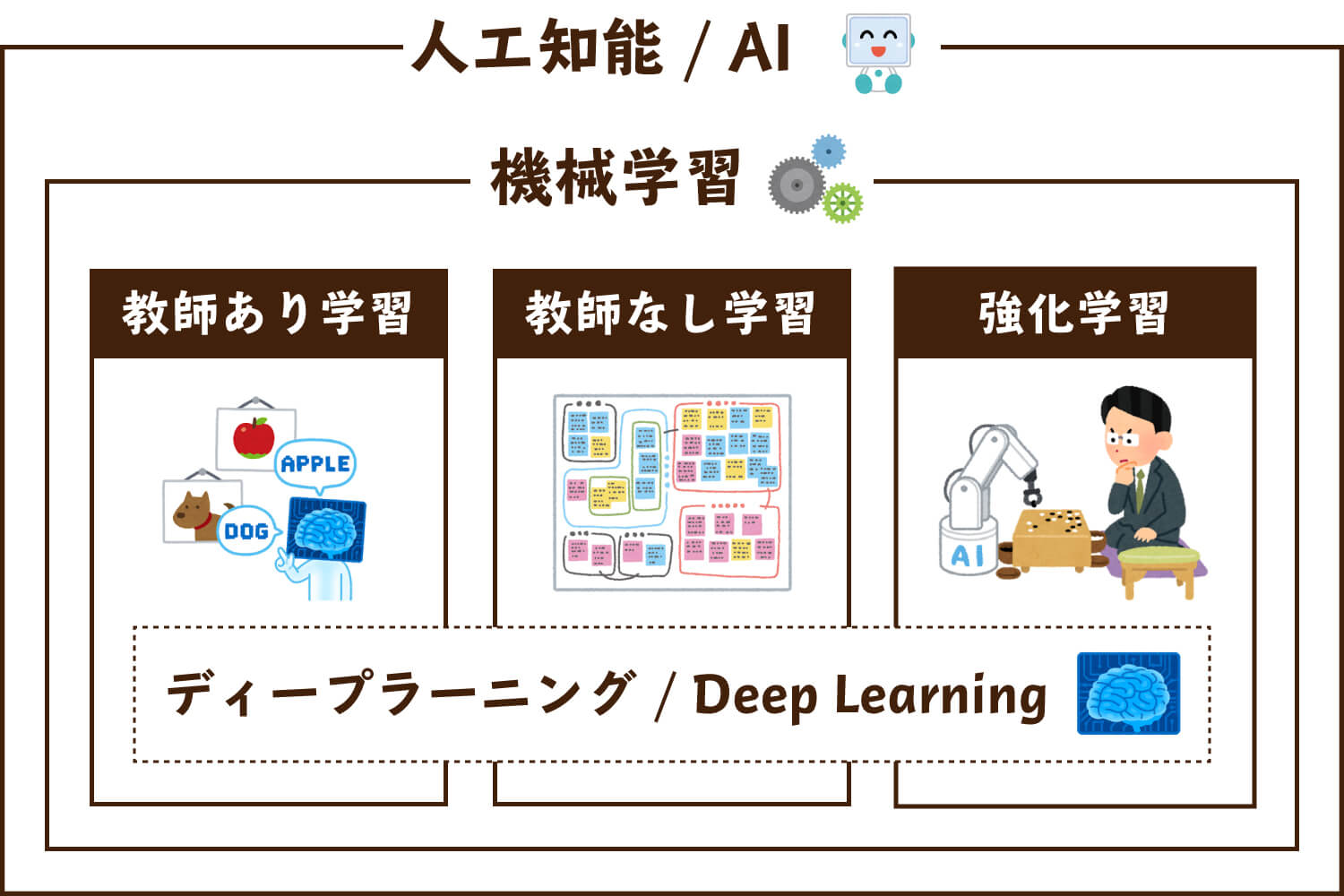
ほかにも機械学習には「教師あり学習」「教師なし学習」といった手法もあり、それらと組み合わせて「ディープラーニング(深層学習)」といった技術も使われたりします。
強化学習によく出てくる用語
強化学習によく出る用語として、以下のような単語があります。
| 用語 | 意味 | 例 |
|---|---|---|
| エージェント | 行動を行う主体 | ロボット |
| 環境 | エージェントが存在する仮想空間 | その場所自体 |
| 状態 | エージェントや環境の情報 | 関節の角度・段差 |
| 行動 | エージェントが行う行動 | 膝の関節を90度に曲げる |
| 報酬 | エージェントの行動に対する即時的な評価 | 前に進んだか |
| Q値 | エージェントの行動に対する将来的な価値 | どれだけ歩けたか |
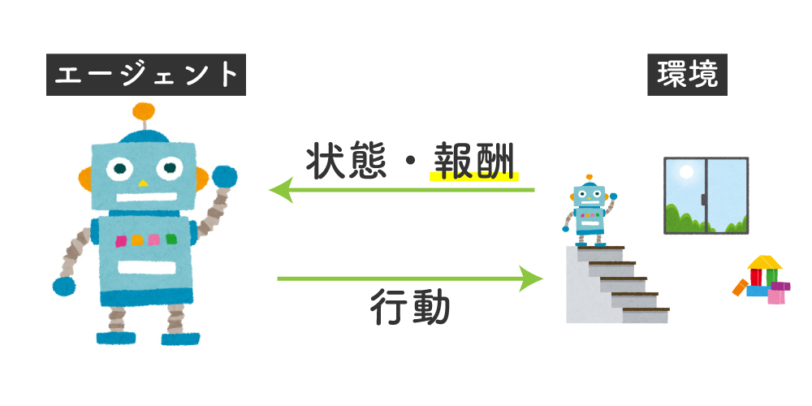
これらの単語を使って強化学習を表現すると、以下のようになります。
強化学習において「エージェント」は、ある「環境」において何かしらの「行動」を起こし、その行動から得られる「報酬」を獲得するという処理を何度も反復することで、報酬の合計が一番大きくなるような行動を学習していく。
少し難しいですが、これが理解できれば強化学習についての理解度も高まっていることでしょう。
強化学習と教師あり学習・教師なし学習の違いは?
機械学習の手法には、大きく分けて「教師あり学習」「教師なし学習」「強化学習」があります。
それぞれの概要について簡単に解説し、どんなところに使われているのかを見てみましょう。
教師あり学習
教師あり学習は、正解ラベルがついたデータを学習する手法です。
画像判別や株価予測などに使われ、未知のデータを判別したり予測したりするために使われます。(分類や回帰と呼ばれる)
簡単に言えば、人間の思い通りの結果を再現するために使われる手法というわけです。
一般的に、正解ラベルの付いた大量の学習用データが必要になるという特徴があります。
教師なし学習
教師なし学習は、正解ラベルがついていないデータを学習する手法です。
特徴の似ているグループに分ける「クラスタリング」や分析の際の変数を減らす「次元削減」など、学習というよりは分析に近いタスクに使われます。
ちょっと難しい言葉を使うと、データの関連性や本質的な構造などを抽出・分析するために使われる手法ということができます。
教師あり学習と違い、出力すべきものがあらかじめ決まっていないことも特徴的です。
強化学習と教師あり学習と教師なし学習の違い
これら3つの手法はそもそも全く異なる手法のため、「どこが違うか」と一言でいうのは難しいかもしれません。
そのため、これらの違いを知りたいのであれば、まずはそれぞれの手法の仕組みを理解すると良いでしょう。
参考までに、それぞれの適用分野についてまとめます。
| 機械学習の手法 | 適用分野 |
|---|---|
| 教師あり学習 | 分類, 回帰, 時系列分析 |
| 教師なし学習 | クラスタリング, 次元削減, アソシエーション分析 |
| 強化学習 | ゲームAI, ロボット制御 |
強化学習の適用例を3つ紹介!
ここからは強化学習の適用例について紹介していきます。
ゲームAI

強化学習は、ゲームAIに使われています。
代表的なものだと囲碁AIの「Alpha Go」や将棋AIの「PONANZA」などが挙げられます。
他にもカーリングAIやボーリングAIなど様々なゲームを解くために強化学習の技術が使われています。
自動運転技術

強化学習は、自動運転技術に使われています。
自動運転技術では、「車や人にぶつからない運転方法」を学習していく必要があります。
なので、ぶつからなかった場合に報酬を与えるような学習をさせて、徐々にぶつからずに運転できるAIを作るのです。
ロボット制御

強化学習は、ロボット制御に使われています。
具体的には、ロボットの姿勢維持のために強化学習が用いられています。
ほかにも工業的なロボットにも使われてたりもします。
強化学習のアルゴリズムは様々!有名な「DQN」って何?
強化学習には様々な手法があります。
ここからは、代表的な強化学習の手法について紹介していきます。
Q-Learning(Q学習)
Q学習は、最も代表的な強化学習の手法です。
Q学習ではQ関数と呼ばれる行動価値関数を学習して、制御します。
行動価値関数とはある状態のときにしたある行動とった場合、その先どれくらいの報酬がもらえそうかを出力する関数です。
1つのステップごとにQ関数を学習していきます。
モンテカルロ法
モンテカルロ法は、Q学習と異なり、最後まで行動をシミュレーションして行動履歴からQ関数を学習するという手法です。
例えば囲碁の場合は対局が終わるまで手を打ち続けて、その履歴からモンテカルロ法Qで学習していきます。
A3C(Asynchronous Advantage Actor-Critic)
A3Cには並列計算とAdvantageと呼ばれる報酬の計算方法が使用されています。
Advantageは報酬の計算を1step後ではなく、数ステップ後まで行動を実施して行います。
なのでより先の行動まで学習できる手法となっています。
DQN(Deep Q-Network)
DQNは、Q学習にDeep Learningを組み合わせた手法です。
Q関数を表すのには、表を使用していました。
この表は「状態s」×「行動の種類」で出来ていました。
いわゆる構造化されたデータです。
ですが、表ではサイズに限りがあるため、ニューラルネットワークを使用したかったですが、うまくいきませんでした。
そこで構造化されていないデータを用いるためにDeep Learningを使用したのがDQNです。
例えば画像も構造化されていないデータですが、Deep Learningで認識できるようになったように表の形になっていないデータに対してDeep Learningは強いです。
DQNの出現でよって、複雑なゲームや制御問題の解決が可能になりました。
強化学習を学ぶなら1番シンプルな「Q学習」からがおすすめ!
これから強化学習について学びたい方は、1番シンプルなQ学習から始めることをおすすめします。
使うプログラミング言語としては、「Python」もしくは「C++」がおすすめです。
あわせて読みたい

Pythonでできること7つと初心者でも作れるもの3つを具体例付きで紹介!
こんにちは!今井(@ima_maru)です。 今回は、近年人気急上昇中のプログラミング言語「Python」について解説します。 Pythonの人気は近年急激に上昇中で、PYPLの人気言語...
強化学習以外のAI技術(教師あり学習や教師なし学習など)についても詳しく学びたい方には、「Aidemy Plemium Plan」というプログラミンスクールもおすすめなので、是非チェックしてみてください。
以上「強化学習とは?教師あり学習との違いなどをわかりやすく解説!」でした!
最後までご覧いただきありがとうございます。